
Postleitzahl-Umkreissuche
Entwicklung eines GIS-Microservice
Zur Einbuchung von lokalen Werbekampagnen werden häufig Postleitzahlen als Targeting benutzt. Daraus ergaben sich für ein Projekt sehr konkrete Anforderungen:

Finde alle Postleitzahlen im Umkreis einer vorgegebenen Adresse
Natürlich gibt es zahlreiche GIS- und Geodatenplattformen, die solche Suchanfragen beantworten können. Die verfügbaren Lösungen waren jedoch deutlich umfangreicher als die eigentliche Anforderung. Wir hätten für Funktionen bezahlt, die wir nicht benötigen, für Preismodelle, die auf wesentlich größere Anwendungsfälle ausgelegt sind, und für zusätzliche Komplexität, die für dieses Produktfeature keinen echten Mehrwert gebracht hätte.
Also fiel die Entscheidung, einen Microservice zu entwickeln, der genau diese eine Kernaufgabe zuverlässig und gut erledigt.
„Ziel: ein Microservice, der genau diese Aufgabe zuverlässig und performant erledigt“
Proportional zur Anforderung

In diesem Beitrag zeigen wir die fachlichen Anforderungen, die geospatialen Implikationen hinter der Umsetzung, die verwendeten Datenquellen und die erreichte Performance.
Das Projekt
Das Ziel war eine REST-API, die eine Adresse und einen Radius entgegennimmt und anschließend alle relevanten Postleitzahlgebiete zurückgibt.
Der Service sollte dabei einige praktische Anforderungen erfüllen:
- eine einfache API für die Produktintegration bereitstellen
- Adressen in geografische Koordinaten auflösen
- deutsche Postleitzahlgebiete per Radius durchsuchen
- ein brauchbares Ergebnis in weniger als einer Sekunde liefern
- ohne unnötige Infrastruktur wartbar bleiben
Auf den ersten Blick wirkt die Aufgabe überschaubar. Eine Adresse wird in Breiten- und Längengrade umgewandelt. Daraus entsteht ein Suchradius. Anschließend müssen nur noch die Postleitzahlgebiete gefunden werden, die innerhalb dieses Radius liegen.
Die eigentliche Herausforderung sind jedoch die Postleitzahlgebiete selbst.
Deutschland verfügt über rund 9.000 Postleitzahlgebiete. Dabei handelt es sich nicht um standardisierte geometrische Einheiten, sondern um historisch gewachsene Flächen mit teilweise sehr komplexen Grenzen.
Ihre Geometrien folgen keinem verlässlichen Muster und können sehr unterschiedlich ausfallen, zum Beispiel als:
- zusammenhängende Gebiete
- geteilte Gebiete
- Gebiete mit Aussparungen oder Löchern
Zusammenhängend

Geteilt

Aussparungen

Damit stellt sich die zentrale Frage der Umkreissuche:
Wann gilt ein Postleitzahlgebiet als „innerhalb des Radius“?
Das Kernproblem
An diesem Punkt wurde deutlich, dass die eigentliche Herausforderung nicht in der Radiusberechnung selbst lag, sondern in der Definition des Suchergebnisses.
Ein Postleitzahlgebiet kann auf unterschiedliche Weise als „innerhalb eines Radius“ betrachtet werden. Wir haben drei mögliche Ansätze diskutiert:
Ein Teil seiner Grenze liegt innerhalb des Radius.
Sein Schwerpunkt liegt innerhalb des Radius.
Ein bestimmter Anteil seiner Gesamtfläche liegt innerhalb des Radius.
Alle drei Ansätze wirken zunächst plausibel. Die Unterschiede zeigen sich jedoch schnell, wenn man ihre Auswirkungen genauer betrachtet.
Ein Teil der Grenze liegt im Radius
Der erste Ansatz wäre, ein Postleitzahlgebiet bereits dann einzubeziehen, wenn irgendein Teil seiner Grenze den Suchradius berührt.
Das klingt zunächst plausibel, kann aber schnell zu sehr großzügigen Ergebnissen führen. Bereits ein kleiner Ausläufer eines Gebiets würde ausreichen, um die gesamte Postleitzahl zurückzugeben. Für manche Anwendungsfälle mag das sinnvoll sein. Für unseren Fall wären die Ergebnisse jedoch zu ungenau geworden.
Hinzu kommt die Performance. Grenzen bestehen aus vielen einzelnen Segmenten. Je komplexer die Geometrie, desto mehr Berechnungen werden notwendig.
Der Schwerpunkt liegt im Radius
Der zweite Ansatz verwendet den Schwerpunkt (Centroid) eines Postleitzahlgebiets. Liegt dieser Punkt innerhalb des Suchradius, wird das Gebiet berücksichtigt.
Der große Vorteil ist die Geschwindigkeit. Es genügt ein einfacher Distanzvergleich zwischen zwei Punkten.
Allerdings repräsentiert der Schwerpunkt nur einen einzelnen Punkt. Gerade bei unregelmäßigen Geometrien kann das zu irreführenden Ergebnissen führen. Ein Gebiet kann weit in den Suchradius hineinragen, obwohl sein Schwerpunkt außerhalb liegt. Umgekehrt kann der Schwerpunkt innerhalb des Radius liegen, obwohl nur ein kleiner Teil der Fläche tatsächlich betroffen ist.
In manchen Fällen liegt der Schwerpunkt sogar in einer Aussparung oder außerhalb der eigentlichen Geometrie.
Falsch negativ

Falsch positiv

Falsch positiv

Der Ansatz war tauglich, für unsere Anforderungen jedoch nicht zuverlässig genug.
Ein bestimmter Anteil der Fläche liegt im Radius
Der dritte Ansatz betrachtet, wie viel eines Postleitzahlgebiets tatsächlich innerhalb des Suchradius liegt.
Dadurch erhalten wir deutlich mehr Kontrolle. Statt nur zu prüfen, ob ein einzelner Punkt oder ein Grenzsegment die Bedingung erfüllt, können wir das Verhältnis der Überschneidung bestimmen oder zumindest annähern.
Das Ergebnis wird dadurch wesentlich aussagekräftiger. Es zeigt nicht nur, welche Postleitzahlen betroffen sind, sondern auch, wie stark sie sich mit dem Suchradius überschneiden.
Eine exakte Schnittmengenberechnung zwischen einem Kreis und mehreren Tausend komplexen Polygonen ist mit gängigen Geospatial-Bibliotheken grundsätzlich möglich. Exaktheit hat jedoch ihren Preis, insbesondere dann, wenn die Antwortzeit unter einer Sekunde bleiben soll und die Laufzeitumgebung bewusst schlank gehalten werden soll.
Deshalb haben wir uns für einen Näherungsansatz entschieden.
Für jedes Postleitzahlgebiet erzeugen wir auf Basis seiner Ausdehnung und seines Schwerpunkts Stichprobenpunkte. Die Implementierung verwendet 3.600 Sample-Punkte mit einer Auflösung von 0,1 Grad.
Zur Laufzeit wird anschließend die Entfernung zwischen dem Suchzentrum und jedem dieser Punkte berechnet. Aus dem Anteil der Punkte, die innerhalb des Radius liegen, lässt sich abschätzen, wie stark das jeweilige Gebiet vom Suchradius abgedeckt wird.
Dadurch bleibt die Berechnung performant und liefert gleichzeitig deutlich mehr Information als eine reine Ja-Nein-Entscheidung.
Das Ergebnis ist ein Wert namens
intersection_ratio, der beschreibt, wie groß die geschätzte Überlappung zwischen Suchradius und Postleitzahlgebiet ist.


Die Datenbasis
Für den Service wurden aktuelle Kartendaten für Deutschland benötigt – idealerweise aus einer offenen und frei nutzbaren Quelle. OpenStreetMap war dafür die naheliegende Grundlage.
Die wichtigste Datenanforderung waren die Geometrien deutscher Postleitzahlgebiete – also die Polygone, die ihre Grenzen beschreiben. Dafür haben wir das
postleitzahlen-Repository von Sebastian Vollnhals verwendet. Es erzeugt Postleitzahlgrenzen aus OpenStreetMap-Daten über die Overpass API und stellt sie als GeoJSON bereit.Für Schwerpunktberechnungen und zusätzliche Metadaten kam außerdem ein CSV-Datensatz des Wissenschaftszentrums Berlin für Sozialforschung (WZB) zum Einsatz, der deutsche Postleitzahlgebiete und deren Schwerpunktkoordinaten enthält.
Der letzte Baustein war die Adressauflösung. Die API akzeptiert Adressen, die Radiussuche selbst arbeitet jedoch ausschließlich mit geografischen Koordinaten. Das System benötigte daher zusätzlich eine Möglichkeit, Adressen in Breiten- und Längengrade zu übersetzen.
Die relevanten Eingangsdaten waren damit:
- die Grenzpolygone deutscher Postleitzahlgebiete als GeoJSON
- die Schwerpunktkoordinaten deutscher Postleitzahlgebiete
- abgeleitete Geometrieinformationen wie Fläche, Höhe und Breite der jeweiligen Gebiete
- eine Offline-Datenbank zur Auflösung von Adressen in geografische Koordinaten
Die Architektur
Nachdem Datenquellen und Formate feststanden, folgte die Architektur einem einfachen Prinzip: So viel wie möglich vor der Laufzeit vorbereiten.
Die vollständigen OpenStreetMap-Daten für Deutschland umfassen mehrere Gigabyte. Diese Daten bei jeder Anfrage erneut auszuwerten, wäre die falsche Architektur. Ein Nutzer sollte nicht auf umfangreiche Datenextraktion warten müssen, während er auf die Antwort einer API-Anfrage wartet.
Deshalb haben wir das System in Vorverarbeitung und Laufzeit aufgeteilt.
Die Vorverarbeitung läuft regelmäßig und erzeugt die Artefakte, die der Service zur Laufzeit benötigt:
- eine GeoJSON-Datei mit den Grenzpolygonen deutscher Postleitzahlgebiete
- angereicherte Metadaten zu jedem Postleitzahlgebiet, einschließlich Fläche, Höhe und Breite
- eine Datenbank zur Offline-Auflösung von Adressen in geografische Koordinaten
Zur Laufzeit werden die Geometrien aller Postleitzahlgebiete im Speicher vorgehalten, sodass Radiusberechnungen ohne zusätzliche Datenbankzugriffe durchgeführt werden können.
Für die Adressauflösung verwendet der Service eine SQLite-Datenbank, die beim Start aus einem S3-kompatiblen Objektspeicher geladen wird.
Für größere Anforderungen wäre eine PostGIS-Datenbank eine sinnvolle Option gewesen. In unserem Fall hätte sie jedoch zusätzliche operative Komplexität eingeführt, ohne einen entsprechenden Mehrwert zu liefern. SQLite, GeoJSON und In-Memory-Geometrieverarbeitung waren für den Anwendungsfall vollkommen ausreichend.
Zum Einsatz kamen:
- Python für Datenverarbeitung und Geospatial-Logik
- FastAPI und Uvicorn für die REST-API
- Shapely für Geometrieverarbeitung
- osmium zur Verarbeitung von OpenStreetMap-Daten
- SQLite für die Adressauflösung
- Docker, CI-Image-Publishing und Helm für Deployment und Betrieb
Genau darin liegt der Vorteil eines fokussierten Microservices: Die Architektur bleibt proportional zur eigentlichen Anforderung.
Das Ergebnis
Am Ende entstand ein Service mit:
- einer Umkreissuche auf Basis deutscher Postleitzahlgeometrien im GeoJSON-Format
- API-Endpunkten für Umkreissuche und Adressauflösung
- einer SQLite-Datenbank zur Offline-Auflösung von Adressen
- vollständiger Containerisierung inklusive Docker, CI-Image-Publishing und Helm-Deployment
Eine vereinfachte Anfrage sieht beispielsweise so aus:
curl -sS -X POST http://127.0.0.1:8008/api/areacodes \
-H "Content-Type: application/json" \
-d '{"address": "Mittelweg 50, 12053 Berlin", "radius": 0.5}'Für einen Radius von 500 Metern rund um unseren Standort liefert der Service mehrere Postleitzahlgebiete inklusive ihres jeweiligen
intersection_ratio.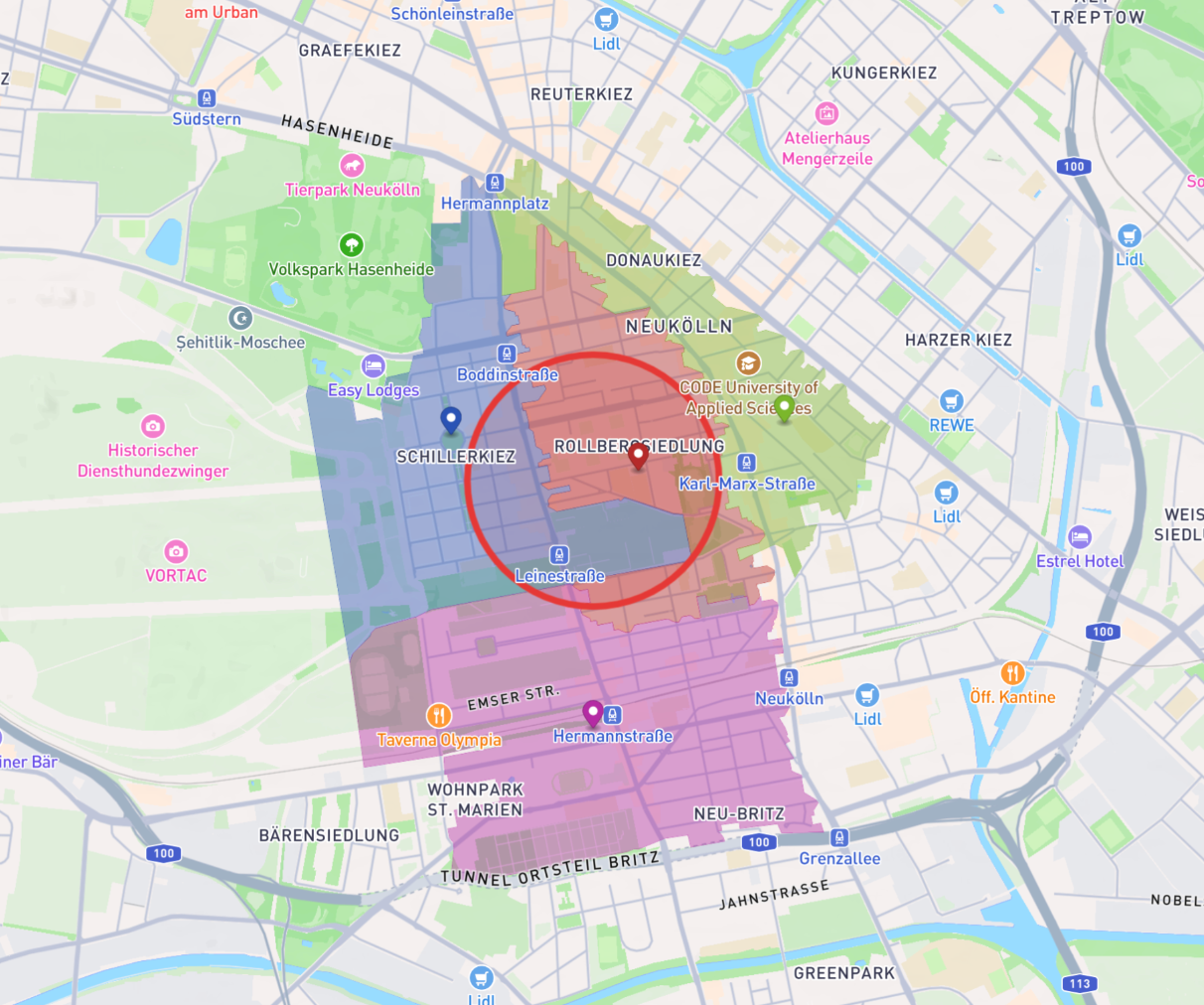
[
{ "areacode": "12053", "name": "Berlin Neukölln", "intersection_ratio": 0.543586 },
{ "areacode": "12049", "name": "Berlin Neukölln", "intersection_ratio": 0.297312 },
{ "areacode": "12043", "name": "Berlin Neukölln", "intersection_ratio": 0.00051 },
{ "areacode": "12051", "name": "Berlin Neukölln", "intersection_ratio": 0.007677 }
]Ein Abgleich mit Google Maps bestätigt die Ergebnisse größtenteils. Rund um die Thomashöhe scheint unser auf OpenStreetMap basierender Datensatz bei den Postleitzahlgrenzen sogar genauer zu sein als die Darstellung in Google Maps.
Zum Beispiel:
Bei einem Radius von einem Kilometer erweitert sich das Ergebnis auf weitere Teile Neuköllns und reicht bereits bis nach Kreuzberg:
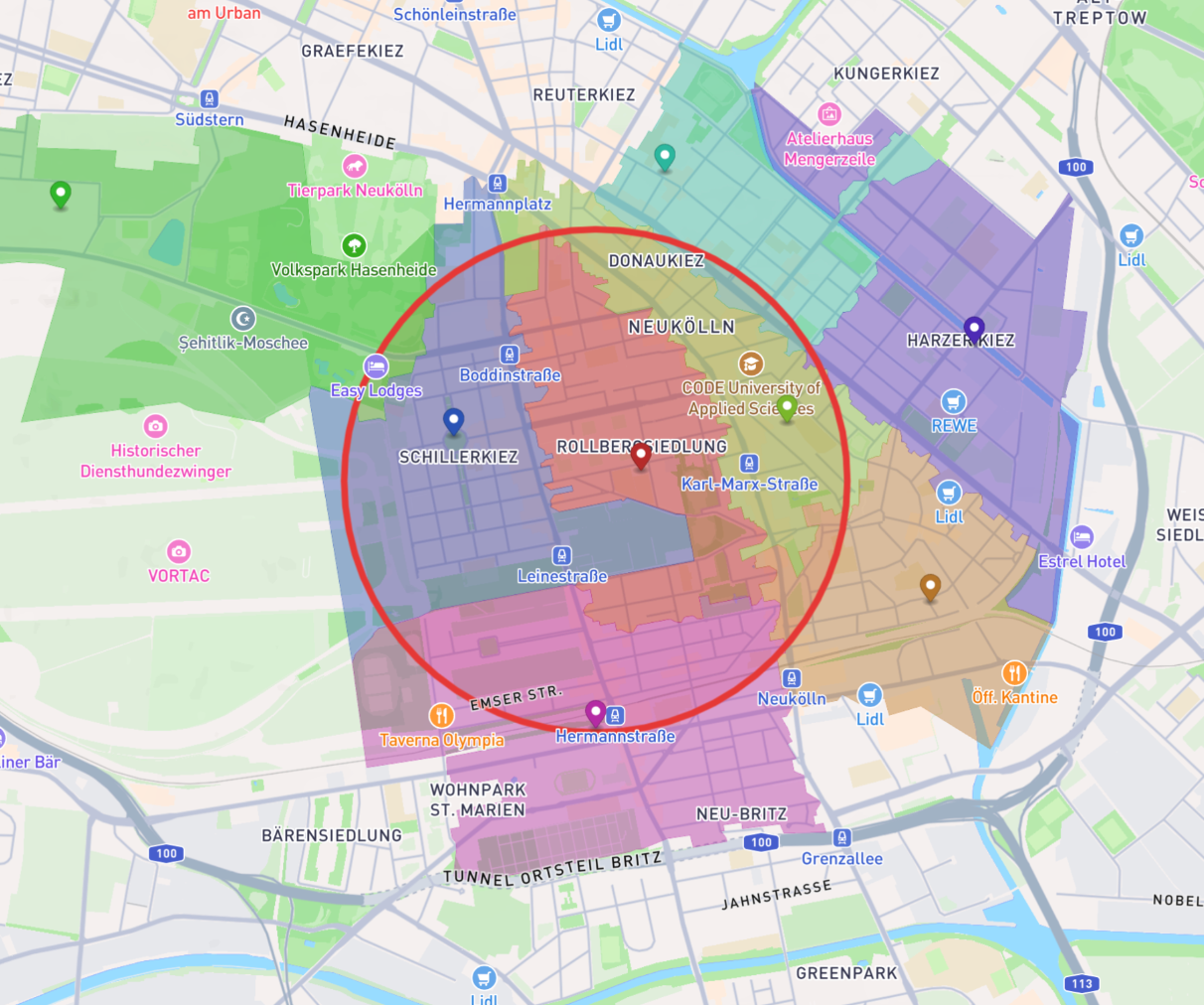
[
{ "areacode": "12053", "name": "Berlin Neukölln", "intersection_ratio": 0.998097 },
{ "areacode": "12049", "name": "Berlin Neukölln", "intersection_ratio": 0.845081 },
{ "areacode": "12043", "name": "Berlin Neukölln", "intersection_ratio": 0.799153 },
{ "areacode": "12051", "name": "Berlin Neukölln", "intersection_ratio": 0.393221 },
{ "areacode": "12045", "name": "Berlin Neukölln", "intersection_ratio": 0.08642 },
{ "areacode": "12055", "name": "Berlin Neukölln", "intersection_ratio": 0.102147 },
{ "areacode": "12059", "name": "Berlin Neukölln", "intersection_ratio": 0.002794 },
{ "areacode": "10965", "name": "Berlin Kreuzberg", "intersection_ratio": 0.020059 }
]Auch hier ist der Vergleich mit Google Maps als Plausibilitätsprüfung hilfreich:
Der entscheidende Wert ist jedoch das
intersection_ratio.Es beschreibt nicht nur, ob ein Gebiet vom Suchradius erfasst wird, sondern wie stark sich Suchradius und Postleitzahlgebiet überschneiden.
Dadurch erhält das konsumierende Produkt mehr Flexibilität bei der Weiterverarbeitung der Ergebnisse. Je nach Anwendungsfall können alle Treffer angezeigt oder sehr kleine Überschneidungen ausgefiltert werden.
Diese Logik muss nicht im Service selbst implementiert werden. Der Service liefert die notwendigen Informationen, während die Entscheidung über Schwellwerte und Filterregeln im konsumierenden Produkt bleibt.
Da die Antworten GeoJSON-kompatibel sind, konnten wir die Ergebnisse komfortabel mit geojson.io visualisieren. Das erleichterte die Validierung erheblich: Anfrage ausführen, die berechneten Postleitzahlgebiete auf der Karte prüfen und kontrollieren, ob die Ergebnisse zur tatsächlichen Geografie passen.
Dabei zeigten sich auch einige der typischen Besonderheiten von Postleitzahlgrenzen. Sie verhalten sich nicht immer so intuitiv, wie man es von einer gewöhnlichen Karte erwarten würde.
Performance
Das Ziel war eine Antwortzeit von unter einer Sekunde pro Anfrage.
Die folgenden Benchmarks wurden lokal auf einem Apple M1 mit 200 Requests, einer Parallelität von 10 und einer kurzen Aufwärmphase durchgeführt.
Selbst bei Suchradien von bis zu 100 Kilometern blieb die durchschnittliche Antwortzeit stabil bei rund 600 Millisekunden.
| Radius | Mean latency | p50 | p95 | p99 | Throughput |
|---|---|---|---|---|---|
| 20 km | 592,89 ms | 571,86 ms | 815,63 ms | 1117,56 ms | ~16,7 req/s |
| 50 km | 622,27 ms | 616,30 ms | 821,18 ms | 973,43 ms | ~16,0 req/s |
| 100 km | 599,29 ms | 573,89 ms | 856,49 ms | 1143,87 ms | ~16,6 req/s |
Mit einer mittleren Latenz von etwa 600 ms – selbst bei einem Suchradius von 100 Kilometern – lag der Service deutlich innerhalb der Zielvorgaben.
Noch wichtiger war jedoch das Gesamtergebnis:
- ausreichend präzise für den Produktanwendungsfall
- schnell genug für interaktive Nutzung
- einfach genug im Betrieb
- unabhängig von umfangreichen GIS-SaaS-Plattformen
- flexibel genug für zukünftige Anforderungen
Fazit
GIS-Plattformen haben ihren Nutzen: Wenn ein Produkt die gesamte Bandbreite ihrer Funktionen benötigt, sind sie häufig die richtige Wahl. Unser Anwendungsfall war deutlich kleiner. Wir brauchten genau eine Fähigkeit: Zu einer Adresse und einem Radius die relevanten Postleitzahlgebiete zu ermitteln.
Wenn eine Anforderung klar abgegrenzt, stabil und zentral für das Produkterlebnis ist, kann ein fokussierter Microservice die bessere technische Entscheidung sein. Er vermeidet unnötige Plattformkomplexität, hält Kosten proportional zur tatsächlichen Nutzung und gibt dem Produktteam volle Kontrolle über Datenquellen, Schwellwerte und Integrationen.
Die Umsetzung war dabei keineswegs trivial. Geodaten bringen zahlreiche Sonderfälle mit sich. Postleitzahlgebiete folgen selten klaren geometrischen Mustern. Präzision und Performance müssen bewusst gegeneinander abgewogen werden.
Mit der richtigen Architektur lässt sich jedoch auch aus einer komplexen Domäne ein kleiner, wartbarer Service entwickeln.
Oft ist ein Microservice für eine spezielle Aufgabe die richtige Lösung.
Gerne unterstützen wir bei der Konzeption, Entwicklung und dem Betrieb maßgeschneiderter Microservices.
Weiterführende Informationen
OpenStreetMap
Zur Website

Sebastian Vollnhals' postleitzahlen-Repository
Zum GitHub-Repository
Postleitzahl-Schwerpunktdatensatz des Wissenschaftszentrums Berlin für Sozialforschung (WZB)
Zum GitHub-Repository
Geofabrik
Tägliche OpenStreetMap-Exporte für Deutschland und andere Regionen.
Zur Website
GeoJSON
Format zur Beschreibung geografischer Datenstrukturen.
Zur Website
geojson.io
Zum Viewer

